3月19日(月)に要求開発アライアンスのセッション『Object-Functional Analysis and Design: 次世代モデリングパラダイムへの道標』を行いましたが、説明を端折ったところを中心にスライドの回顧をしています。
今回は「Data Context Interaction (DCI)」として用意した以下のスライドを説明します。

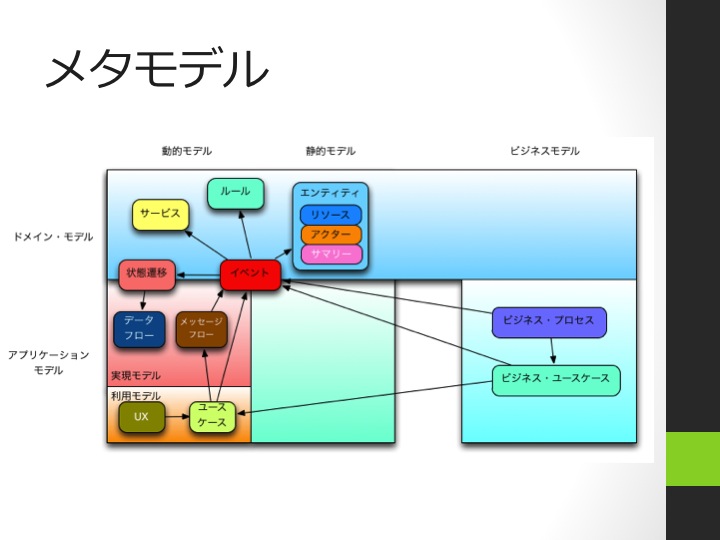
オブジェクト・モデリングの問題点の一つに、ユースケースからドメイン・オブジェクトへ真面目に責務の分散配備をしていくと、ドメイン・オブジェクトの実現が非常に重たくなってしまうという問題があります。
ドメイン・モデルそのものに由来するドメイン・ロジックをドメイン・オブジェクトで実現するのは、本来のオブジェクト指向の趣旨にも則っており問題ありません。
論点となるのはユースケース由来のアプリケーション・ロジック。このアプリケーション・ロジックを、(1)どのようにして適切な責務に分解して、(2)どのオブジェクトに分散配備していくのか、というのがオブジェクト・モデリングのホットスポットで、オブジェクト・モデリング手法を比較する上でのポイントとなるところです。
大きく、ドメイン・オブジェクトに配備していく派と、アプリケーション・ロジックを別オブジェクトで実現する派に分かれますが、理論的な主流派は前者、実際の開発者は後者を選ぶというねじれ状態になっています。
それはともかく、責務をドメイン・オブジェクトのみに配備していくと、システムを取り巻く文脈ごとのユースケースで必要な責務を集積した、巨大な責務の集りをドメイン・オブジェクトがまとめて実現することになり、(1)太ったドメイン・オブジェクトになってしまうという問題が出てきます。これに加えて、(2)色々なユースケースの断片が分散配備されることは、モジュール化、疎結合、高凝集という観点からも問題です。また、(3)モデルのライフサイクルの違いの扱いも論点の一つです。(3a)比較的安定しているデータモデル、(3b)比較的ライフサイクルの短いアプリケーション・ロジック、(3c)比較的高頻度に更新されるUIロジックを同じモジュールに配備すると、(3a)のUIや(3b)のアプリケーション・ロジックに引きずられ(3c)のデータモデル(を扱う処理部)にも影響が出てしまいます。
(1)は集中することの問題、(2)は分散することの問題、(3)は集中することの問題なので、それぞれ相反する事象であり、全てを一度に満足することは困難です。程よく集中して、程よく分散するバランス点を見出し、プログラミング言語での自然な実装手法を確立していく必要があります。
この問題に対する解として一時期AOPが注目されましたが、あまりうまくいっていないようです。柔軟すぎるメカニズムは、プログラムの安全性という意味で問題がありそうです。静的型付けの枠組み内でこの問題を解決するのが、安全性を担保するひとつの目安だと思います。
この問題を解決するアプリケーション・アーキテクチャとして注目されているのがDCI(Data Context Interaction)です。
- Data, context and interaction
- The DCI Architecture: A New Vision of Object-Oriented Programming
- Lean Architecture: for Agile Software Development (書籍)
このスライドでは、OFPが提供するトレイト、型クラスという新しい言語要素(「OFP新三種の神器」)が、DCIといった新しいアプリケーション・アーキテクチャを可能にするという点の説明を行う予定でした。
モデリングの流れ
DCIのモデリングの流れとしては:
- ユースケース・モデルの作成
- コラボレーションとコラボレーションから呼び出すロールを抽出
- コラボレーションを実現するアプリケーション・ロジックを分解してロールに配備
- ロールをドメイン・オブジェクトに編み込み。コンテキストで全体を統合。
となるかと思います。ボクが確認した範囲では、アプリケーション・ロジック専用のオブジェクトを生成したり、コンテキスト側でアプリケーション・ロジック(の一部)を実現するのではなく、あくまでドメイン・オブジェクトに編み込むロールにロジックを分割するようです。
つまり、この理解が正しければユースケースの責務をドメイン・オブジェクトに分割配備する伝統的なオブジェクト・モデリングの手法を軸としながら、ユースケース由来の責務をコンテキストに紐づいたロール側に配備することで、モジュール化を実現しているのがDCIということになります。
実装技術
ロールをオブジェクトに編み込む実装技術として、トレイトと型クラスが有力です。
現時点では、書籍の「Lean Architecture: for Agile Software Development」がDCIについて最も情報量があるのではないかと思います。この本では、DCIについての主な実装方法として、CとRubyの2つの言語での実装が主に取り上げられており、付録としてScalaも取り上げられています。
Cの実現はマクロを使ったものでやや強引な印象です。Rubyの実現はmoduleを使った動的型付ならではのメタプログラミング的な手法で、プログラマに負担をかけないのが美点です。
ただ、普通の静的型付け&OOPでの実装技術となるとなかなか難しく、Javaで実現する場合は相当量のボイラープレイト、繋ぎコードが必要になりそうです。この問題に対する解として期待されるのがScalaのトレイトです。
トレイトによる解
DCIでは、Scalaのトレイトによる実装を選択肢の一つとして挙げています。たとえば、「Lean Architecture」で紹介されているプログラム例の一部を以下に引用します。
val source = new SavingAccount with TransferMoneySource val sink = new CheckingAccount with TransferMoneySink source.increaseBalance(100000) source.transferTo(200, sink)
SavingAccountクラスのオブジェクトを生成する時に、ロールを実現したTransferMoneySourceトレイトをwith句で編み込んでいるのがポイントです。この(ユースケース由来の)アプリケーションロジック向けの機能を事前にSavingAccountクラス側で提供しておく必要はなく、アプリケーションロジックでの必要に応じてロールを編み込みます。ユースケースから派生したロジックを、直接ドメイン・オブジェクトに分散配備するのではなく、ユースケースに紐づいたロール側にまとめておけるのでモジュール化も保てるというわけです。
型クラスによる解
Scalaでは、トレイとに加えて、型クラスという新しい言語機能が提供されています。(正確には暗黙パラメタと暗黙変換によってライブラリで型クラスを実現することができます。)型クラスは、基本的にはジェネリックプログラミングのカテゴリの言語要素だと思うのですが、Haskellで実用化され、関数型の枠組みの中でうまく機能しているのでたので広義の意味では関数型の特徴的な言語要素ということも可能かと思います。
Scalaでの実現であるScalazを実際に使ってみると"OOPにも型クラスの導入が可能で、実用上も有益である"のかなと思いますが、プログラミング言語理論は素人なので、このあたりの事情はよくわかりません。
ひとつ言えるのは、Scalaでは型クラスは非常にうまく機能しており、Scalaの提唱するObject-Functional Programmingの重要な基盤の一つになるだろう、ということです。
DCIをトレイトで実装する場合の問題点は、with句を使うコーディングとなるのでロールをドメイン・オブジェクトに編み込むところがハードコーディングとなることです。コンテキストが複数のロールを扱うときに、これらのロールを束ねるメカニズムもないので、このあたりで拡張性やモジュール化で問題が出てきそうです。
型クラスの場合は、コンテキスト毎にアプリケーション・ロジック、ロール、ドメイン・オブジェクトの対応関係の組を柔軟に指定することができるので、拡張性、モジュール化の能力に優れているのではないかと思います。そういう意味で、トレイトではなく型クラスが、ScalaにおけるDCI実現の本命ではないかと考えています。
DCIの評価
「このスライドでは、OFPが提供するトレイト、型クラスという新しい言語要素が、DCIといった新しいアプリケーション・アーキテクチャを可能にするという点の説明を行う予定」だったわけですが、改めてじっくり検討してみると、DCIはとても魅力的なアプリケーション・アーキテクチャではあるものの、実際のシステム開発への展開はまだまだ難しそうというのが実感です。
また、アプリケーション・ロジック専用のオブジェクトは第一級のモデル要素としては考えていないというのが、DCIがボクの好みとずれがある点です。ボクとしては、アプリケーション・ロジック、ロール、ドメイン・ロジックの3階層で責務の分割配備を考えたいと思っています。(このようにして抽出したアプリケーション・ロジックは、ドメイン・ロジックそのものなので、ドメイン・ロジック&ドメイン・オブジェクトとしてドメイン・モデル内に還元する、という考え方であればDCIとは矛盾しません。どちらの考え方にした方が、実際のアプリケーション開発で有効なのか、もう少し様子をみて判断したいと思っています。)
以上がOFADについてひと通り通して考えてみた上での実感です。
EDA
アプリケーション・ロジック、ロール、ドメイン・ロジックの3階層で責務の分割配備を行うためには、DCIでいうところのコンテキストを、アプリケーション・ロジックを配備するモデル要素に格上げするような、アーキテクチャが有効ではないかと考えます。仮にこのモデル要素をコラボレーションと呼ぶことにしましょう。(「コラボレーション」という用語はミスリードのような気もするので、他の名前を編み出したほうがよいかもしれません。)
このコラボレーションを、実際のアプリケーション・アーキテクチャに組み込む場所ですが、クラウド・アプリケーションでは、「EDAとオブジェクトと関数」で取り上げたEDAをベースとしたアーキテクチャが有力ではないかと考えています。
このアーキテクチャにあるコラボレーションをイベント・コンシュマーとしてEDA内に組み込むわけです。この時に、コラボレーションの通信相手となるロールを型クラスの機能を用いてドメイン・オブジェクトに編み込みます。
この方式では、イベント発生に付随した複数の疎結合のユースケースが並行動作することを自然に扱うことが事ができます。また、EDAの特質上、非同期処理も自然に扱えるのという長所もあります。
そういう意味で、DCIというアーキテクチャを単独で考えるのではなく、EDAのアーキテクチャの中にDCI的なアプローチも取り込みながら、EDAの枠組みで全体のアーキテクチャ(モデリング・ビュー、コンポーネント・ビュー)を考えていくのが、クラウド時代のOFADを整備していく上で有力なアプローチではないかというのが現時点での考えです。
諸元
当日使用したスライドは以下のものです。(PDF出力ツールの関係で、当日は非表示にしたスライドも表示されています)
このスライド作成の様子は以下の記事になります。
- 関数型言語の技術マップ
- オブジェクト・モデリングのボトルネック
- 代数的構造デザインパターン
- 圏論デザインパターン
- オブジェクトと関数の連携(1)
- オブジェクトと関数の連携(2)
- オブジェクトと関数の連携(3)
- データフローの実装技術
- 関数型とデータフロー(1)
- 関数型とデータフロー(2)
- 関数型とデータフロー(3)
- 関数型とデータフロー(4)
- DSL駆動によるクラウド・アプリケーション開発
- OFADの要素技術/関連技術
まとめは以下の記事です。
回顧は以下の記事になります。